- Published on
- • 4 min read
Stop Redesigning Chat Databases: The Case for a Universal AI ORM
- Authors

- Name
- Shaiju Edakulangara
- @eshaiju
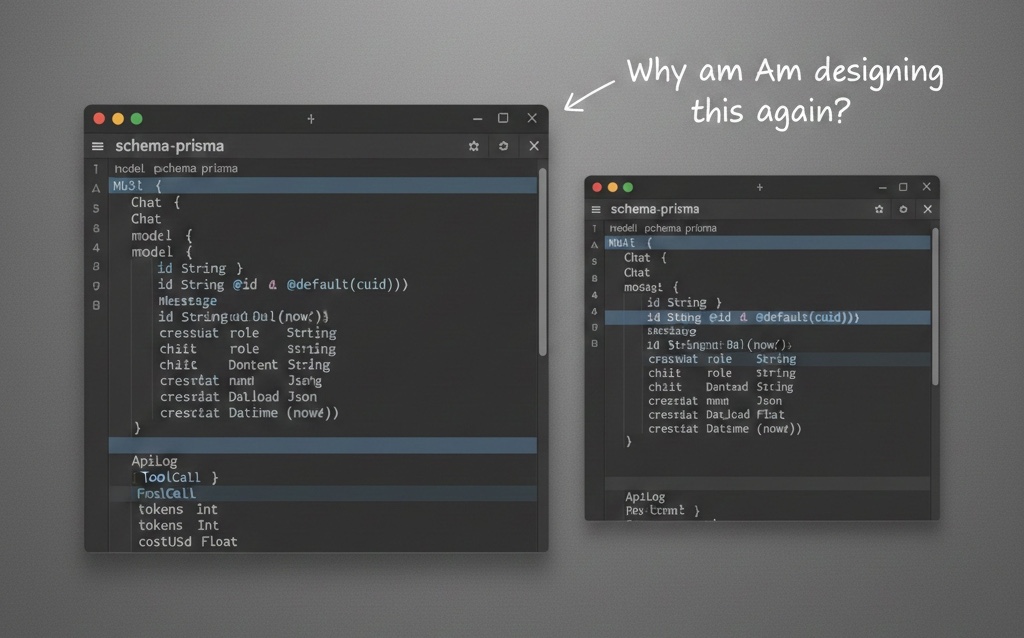
Every time I start a new AI project, I find myself performing the same repetitive ritual: designing the same four database tables.
- Chats (the session)
- Messages (the history)
- Tool Calls (the audit trail)
- API Logs (tracking the $ cost)
We spend days writing boilerplate upsert logic, juggling Prisma schemas, and trying to figure out how to save a message that is currently being streamed in real-time.
In the Rails world, we solved these "boring" problems years ago with conventions. With NodeLLM, we’re bringing those same engineering practices to the Node.js AI ecosystem—standardizing the plumbing so we can focus on building features that matter.
The "Stateless" Illusion
Official LLM SDKs (OpenAI, Anthropic, Gemini) are brilliant, but they are intentionally stateless. They are raw pipes. They don't care about your database, your user session, or the fact that your connection might drop halfway through a 500-token stream.
My job isn't to write "cool" AI code; it's to build systems that don't leak state and don't require a total rewrite when we switch from GPT-4 to Claude.
Why Persistence is Harder than it Looks
It sounds simple until you hit production:
- The Streaming Gap: If you save the message after the stream ends, you’ve already made a transactional mistake. If the user closes the tab at 90%, you’ve lost the history.
- The Tool Audit Trail: If your model calls a
serp_searchtool, where do you store the raw result? If you don't store it, how do you debug a "hallucination" three weeks later? - Multi-Provider Schema: OpenAI returns usage in one format; Gemini in another. Standardizing these into a single Cost column shouldn't be your weekend project.
Introducing @node-llm/orm
We built @node-llm/orm to provide ActiveRecord-like conventions without the framework lock-in. It doesn't replace your database; it simply teaches your LLM how to talk to it.
import { createChat } from "@node-llm/orm/prisma";
// This chat object is now "smart."
// Every ask() and stream() call is automatically persisted.
const chat = await createChat(prisma, llm, {
userId: "user_123",
model: "gpt-4o"
});
await chat.ask("What is our Q3 travel policy?");
By bringing convention to the data layer, we've reduced hours of database boilerplate into a single line of code.
Out of the box, it handles the persistence of your entire AI lifecycle:
- Conversation State: History, system prompts, and hidden "reasoning" blocks.
- Tool Audit Logs: Every tool call, its arguments, and the raw results.
- Usage Metrics: Token counts, cost tracking, and request latency.
More importantly, we've created a system that is audit-ready by default.
npm install @node-llm/core @node-llm/orm
The full suite of tools is available on NPM.
What This Is Not
Senior engineers look for scope discipline. To be clear about the boundaries, @node-llm/orm is:
- Not a framework: It doesn't own your application lifecycle.
- Not a database: It sits on top of your existing Prisma/Postgres/MySQL setup.
- Not a hosted service: Everything runs in your infrastructure.
- Not opinionated: We don't care about your UI, auth, or internal business logic.
The Hubris of "Hand-Rolled"
There is a certain hubris in thinking we need to design a custom database schema for every AI feature. Most of the time, we just need the history to stay put, the tools to be logged, and the costs to be tracked.
Stop redesigning the plumbing. Start building the features.
If you’ve ever redesigned the same four AI tables twice, this is for you. Check out the @node-llm/orm documentation.